Adding fibers to v8: efficiency + clarity in SSJS


Historically, webapp development has required painful trade-offs between code clarity and performance. This is the story of how we added cooperative threading to server-side JavaScript (v8) to get the best of both worlds.
When prototyping, you make rapid progress by ignoring performance and writing code that closely mirrors your mental model of what your application does. The transition to a scalable production service generally requires rearranging code to minimize requests to the storage layer, making the code harder to read and change. To build an application of Asana’s complexity, we need the simplicity and agility of prototype code with the performance of production code.
This project was done as part of our work on the Luna framework, the programming environment we’re developing in-house in order to deliver the rich functionality and extreme responsiveness of the Asana product (currently in beta).
Simplicity versus database performance
Prototypes can pretend that the web server has random access to all data, hitting the database serially every time UI code accesses a value. But high-performance webapps need to minimize database (or memcache, etc.) roundtrips. So on the one hand, we want to batch database queries as aggressively as possible, across different parts of the page. On the other hand, for clarity we want code that loads data to be near code that renders that data.
The joy of prototyping
Imagine we’re building a simple two-pane webmail client. The left pane shows each folder, annotated with its unread message count. The right pane shows each message in the selected folder, displaying its subject and a snippet of its body.
If we don’t care about performance we can write simple, clear code:

Batching
The problem is that we actually do care about performance. The code above makes a serial request to the database for each message and for each folder, adding latency for each request. To improve on this we need to execute multiple database requests at once.
Different storage and caching systems have different ways of combining requests. For example, MySQL supports multiple statement execution. Using one of these batching APIs is easy. The hard part of batching is changing the application to use it. Let’s explore some ways to do this.
Manually batching requests
We can restructure the code to collect the initial reads in one place. After those, we can do any reads that depend on results from the first reads. In our example, we need to read the message counts after reading the list of messages. In fact, for any page there’s some sequence of dependencies that represents the critical/longest path, and ideally our page would load in exactly that many database requests. Using a dependency graph to describe an application’s data needs, we can discover the best-case number of round-trips to the database: the graph’s height.
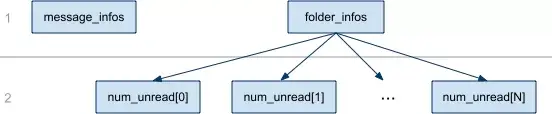
Data dependency graph for mail client.
The prototype code above makes a request for every node in the graph, instead of just the two required. If we manually arrange the reads to be optimal, we get:
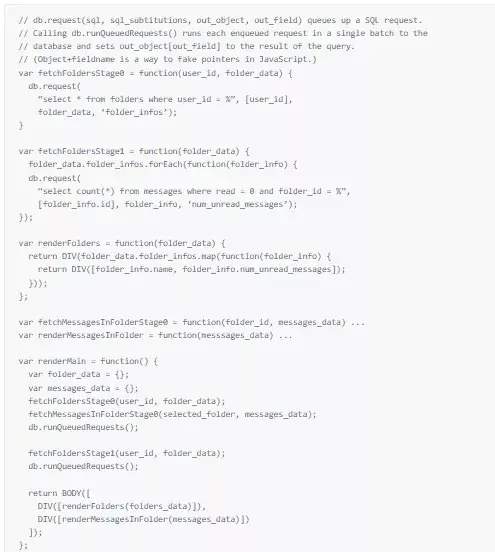
This code makes only two requests to the database: one for each level of the dependency graph. However, it is harder to read and modify than the first version. Changing how one part of the page renders requires modifying the fetch and render functions in complex error-prone ways. (A common mistake is removing render code but forgetting to remove the corresponding fetch code.) We also broke encapsulation by forcing renderMain to understand how many batches are required for each component.
Asynchronous programming
Asynchronous programming lets us keep the fetching and rendering code together while batching otherwise serial requests. We do this by defining callbacks to run after data has been loaded.
Here’s an asynchronous version of part of the code:

Fun, huh? We find asynchronous code longer and harder to read (and write) than synchronous code. Debugging is harder because the original stack is lost by the time a callback is run. Even in this simplified example, the code is significantly more obtuse.
Clarity + Performance = Fibers
Threads let engineers write code that runs asynchronously but looks synchronous, with meaningful stack traces and clearer control flow. But traditional preemptive multithreaded programming is notorious for introducing subtle race conditions. Fibers are cooperative threads that let programmers explicitly define when each thread should pause and resume. With fibers, we can write efficient code that looks almost like prototype code – and without the heisenbugs of preemptive threading.
Fibers allow us to write a simple system for batching database requests. We start building the page on one fiber. At various points the code spawns more fibers to work on independent parts of the page, each pausing as soon as it needs to read from the database. Once all fibers are blocked, we perform all queued-up requests in a single batch, and then resume the blocked fibers.
Most of these fibers are introduced by our framework. For example, we have a version of map() that starts a fiber for each item in the array and waits until those fibers have finished before returning the output array. In other cases, such as around the example’s calls to renderFolders() and renderMessages(), we explicitly create new fibers.
Here is a fibered version of renderMain(). (The rest of the code didn’t need to change from the prototype version.)
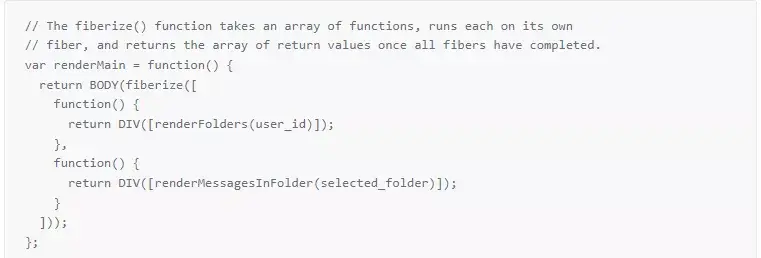
This diagram shows in more detail what happens during fiberize() or map(). Remember that we wait until all fibers are blocked before sending a request to the database. That means that two worker fibers can each call fiberize() or map() and the database requests from all of the resulting fibers will be combined into a single batch.

Using fibers lets us combine into one database request the reads from completely different parts of the code. Code that looks very similar to the initial prototype code now runs with the optimal number of database requests: one per level of the data dependency graph.
Implementing JavaScript fibers in v8
Few languages support fibers natively (though support was recently added to Ruby). We write most of our server code in JavaScript and run it under Google’s v8 engine, the same JS runtime that Chrome uses. Fortunately the v8 codebase is excellently structured, so we were able to add fiber support in just a few days. We made our changes in v8cgi, a library of server-oriented extensions to v8. (Look for fibers.cc.).
Here’s a sample of the API:
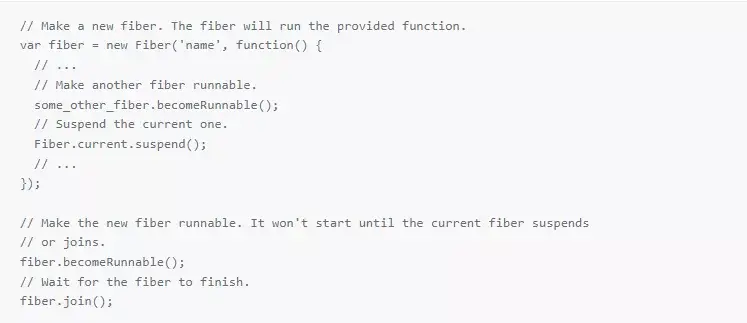
That’s almost the entire API. We don’t need any synchronization primitives because only one fiber runs at a time and control only changes when suspend() or join() is called.
Conclusion
There is a tension between writing clear, well-abstracted code and writing code that makes efficient use of the database. Adding fibers to v8 allowed us to resolve this tension. In taking a small amount of time to solve this problem right, we have made our entire engineering team more efficient for the long run.
Simplicity; performance; w00t.
Excited by this technology and passionate about products that improve the efficiency of communication? We’re hiring.



