Part 1 – WorldStore: Distributed caching with Reactivity


This post is the first in a two-part series on how we implemented distributed caching in a fully reactive framework.
As part of our application framework overhaul [1] a few years ago, we built LunaDb [2], a reactive data system to underpin the Luna web framework. While LunaDb has worked well, Asana’s growing scale and complexity exposed some bottlenecks in the system which prevented us from reliably deploying new code. To address this, we introduced WorldStore, a service that functions as a data loading layer with a distributed cache. In this post, we’ll discuss why we needed to add this additional layer, and describe some of the technical challenges of adapting our existing reactivity pipeline to work with a distributed cache.
Background on the Luna Framework
The Luna framework describes its own spec for loading data via projections.
A projection is a collection of data defined by a single root object and objects connected to it through data model relationships. So a projection over an Asana project could look like:
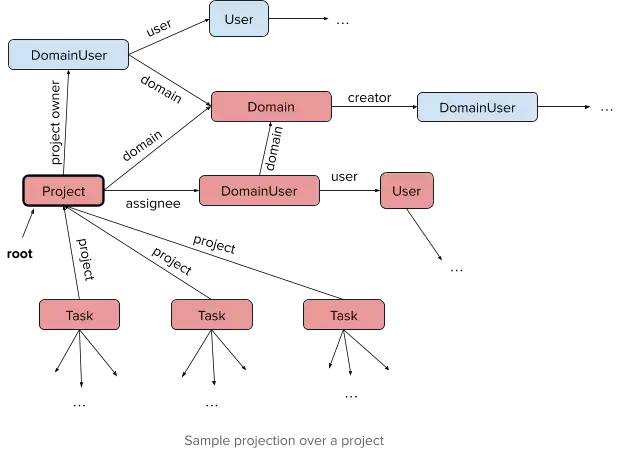
Functionally, projections resemble queries in GraphQL.
Luna is a framework for declarative data fetching, which means there are two interesting data flows:
How does a client request data?
How does the backend keep the client up-to-date?
Requesting Data
Asana follows a client-server architecture where web clients talk to the backend system (LunaDb) via sync servers. Sync servers are composed of stateful processes that serve and maintain (i.e. keep up-to-date) data via websockets.
Let’s take a look at the typical read path for a web client:

A connected web client requests a projection through the sync protocol [3]. A sync server then requests the underlying objects from the database, computes the projection from the results, computes access control if necessary, and returns the results. Additionally, the sync server keeps track of the data the client has requested. These requests for updates to data are called subscriptions, and a client can subscribe/unsubscribe to/from data as necessary.
Maintaining Data
Sync servers maintain client subscription mappings, but they do not track all data changes. Instead, this role is delegated to a separate process known as an invalidator.
MySQL databases produce a replication log (a.k.a. binary log or binlog), a stream of linearized transactions committed to the database. Each transaction is sequenced by a binlog sequence number (BSN), effectively making a BSN a global version for the DB. An invalidator tails the replication log of the database and streams notifications about data changes, also called invalidations.
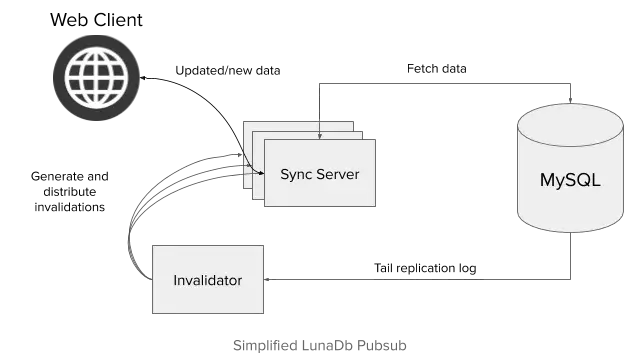
Sync servers tail these invalidation streams and fetch corresponding new data for each invalidation that relates to a stored client subscription. The new data is then sent to clients over the web socket.
Sync servers track their progress in the invalidation stream using the BSN associated with each invalidation. If the invalidation stream breaks, a sync server can request to start tailing invalidations again from the same position.
Sync Server Caching
Computed data is memoized on each sync server to avoid database round trips and reduce load. To avoid serving stale data, the cached data is invalidated based on the content of the invalidation streams.
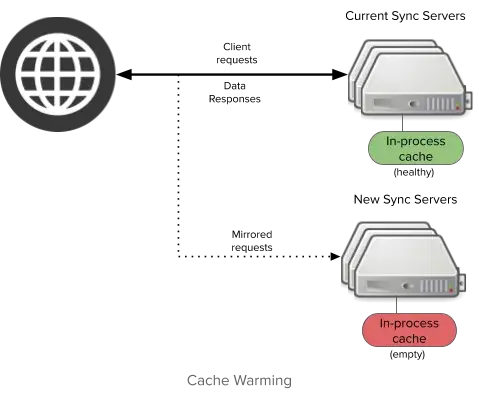
While in-process caching performs pretty well, it has one distinct weakness. It adds a strong requirement for sync servers to have healthily populated caches. Unfortunately, new server deployments will always start up with empty caches. How do we deal with this?
Our initial solution was to introduce a mechanism called cache warming to prepare new deployments. Cache warming mirrors traffic to servers in a new deployment for enough time to populate healthy in-process caches, around 20 minutes.
This approach solves the immediate problem of insufficient caches, but comes at the cost of significant compromise. With cache warming, new deployments:
Add a non-trivial amount of load to databases, preventing us from deploying new code during peak traffic.
Do not protect databases from server crashes / restarts (would clear in process caches).
Take a long time to become ready, slowing down our ability to deploy hotfixes during incident response.
When we first built LunaDb, these were compromises that we could live with. However, as our number of users grew, so did the load on the database, making deployments riskier for database health, and making it increasingly difficult to reason about the effects of deploying new code. As our team grew, our rate of automated deployments (once a day) started bottlenecking developer velocity because of the deep ties between the Luna web framework, and the LunaDb server code. It was clear that we couldn’t keep relying on this approach in the long-term.
Our solution was to add a distributed caching layer that is independent of the deployment lifecycle of sync servers. The service that encapsulates it is WorldStore.
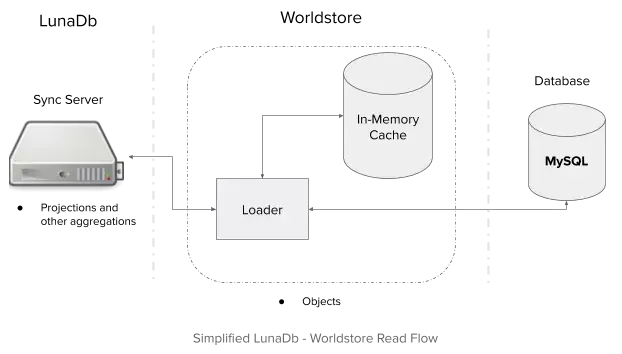
The WorldStore Service
Formally, WorldStore is a service that functions as a data loading layer for objects between LunaDb and the database. It caches results in an in-memory data store (ie. Redis) to protect the database from load.
With WorldStore, sync servers no longer directly connect to the database to fetch data. Instead, sync servers connect to loader servers. A loader, as the name suggests, loads objects given a corresponding request.
The processing of a projection request at the sync server is also now logically split-up between services:
WorldStore (i.e. loaders) manages fetching objects
LunaDb (ie. sync servers) transforms the objects into shapes the web clients expect [4]
The key challenge in implementing this specification was with cache invalidation. In other words, how could we adapt our existing invalidation pipeline to work with a distributed cache?
In Part 2 of this series, we’ll jump into the details of designing WorldStore and scaling it to meet production requirements.
1. We’ve previously written about the evolution of the Luna framework and our performance re-write
2. A short talk about the high-level design of LunaDb during its initial development
3. A protocol for clients to request data, and for servers to keep clients up-to-date for all requested data. The full protocol is out of the scope of this document, but may be included in future posts.
4. Projections and other aggregations are composed of objects. An entire projection is technically invalidated by a single constituent member being invalidated. As such, we will not explicitly consider them when discussing the invalidation pipeline.
Special thanks to Brandon Zhang, Theo Spears, Ashley Waxman, Michiel Wong Baird, Natan Dubitski, Sean Wentzel, Steve Landey, Andrew Budiman