How Asana ships stable web application releases



The majority of our product code—our large client bundle, our back-end mutation server, our distributed job system—are shipped together as a single web release. We’ve built systems that allow us to continue to ship web releases safely, three times a day, even as our engineering team and product codebase grow geometrically. In this blog post, I’m going to describe how we do it. But first, I’d like to start with a story that illustrates how some of the pieces of our application stability and deployment systems work together at Asana.
On the morning of Tuesday, August 11, at 9:03 a.m., our web on-call engineer George Hyun received a message in Slack from our Release Activation System. It told him that the new web release we had just deployed at 9 a.m. (Release C, in the diagram below) was broken, and it recommended that he roll back the release.
An error had just started occurring in the signup flow, and Airpedal, our home-built error-reporting tool, had just created a blocking broken release range for this new error, because it was happening at a very high rate on the new release only. The error had happened to only 5 users so far, but this was after serving the release for just 3 minutes.
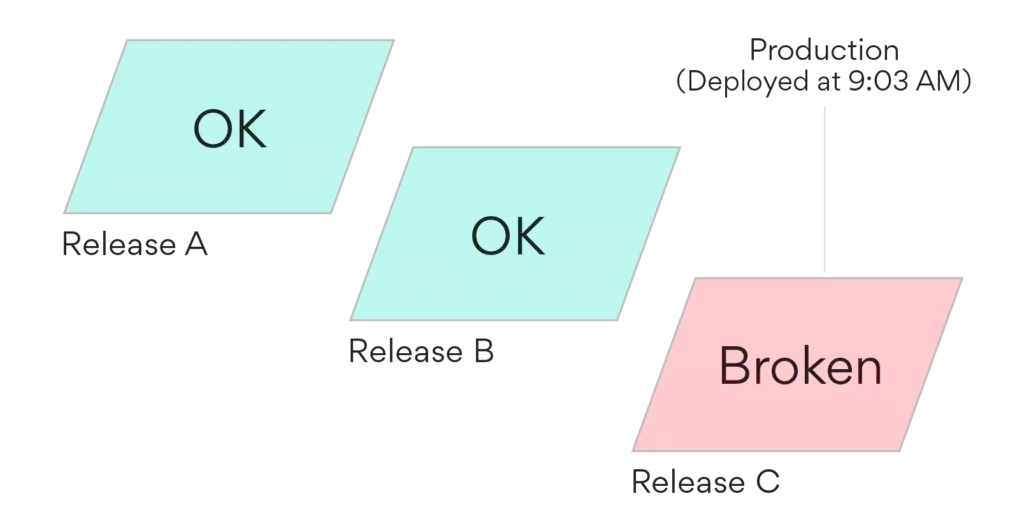
George looked at the Airpedal error logs, confirmed it was a serious problem, and enqued a rollback of the web release to the most recent good production deployment (Release B). The rollback completed at 9:10 a.m., by which point 19 signups had failed due to this crash. If this had taken an hour to recognize and handle, we could have seen over a hundred failed signups, which could impact our business.
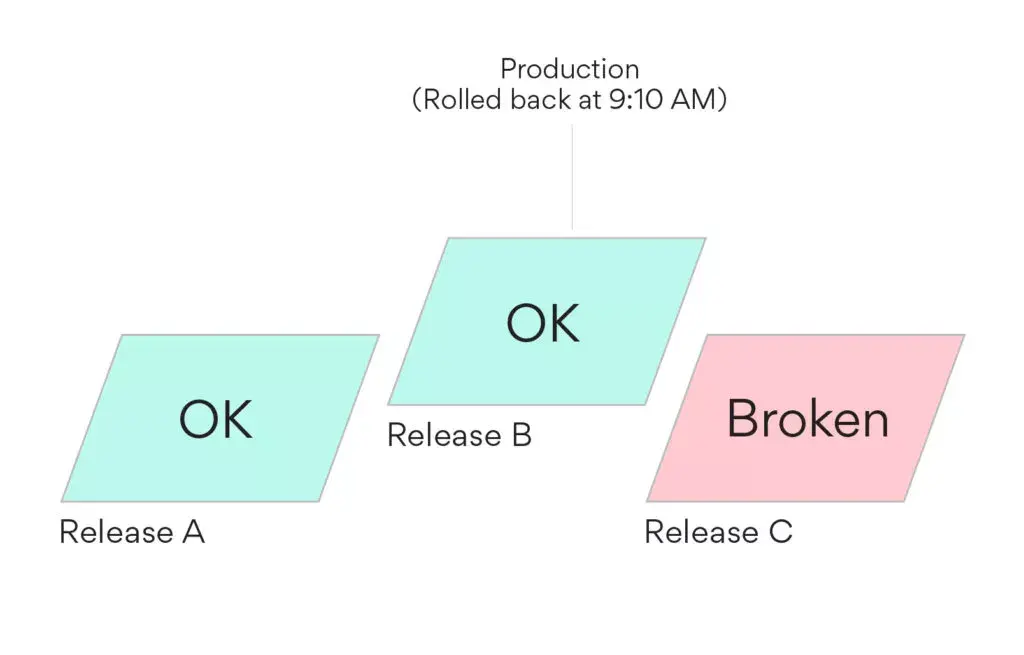
The first thing to do was to revert the commit that caused the problem, and merge that fix. However, the release we had rolled back from had had some important last-minute fixes for a product launch, so additionally, George cherry-picked his revert-fix of the signup bug on top of the rolled-back release, built a new release (Release D) from that, and pushed it to production. At no point did he lock or stop our automatic deployment system.
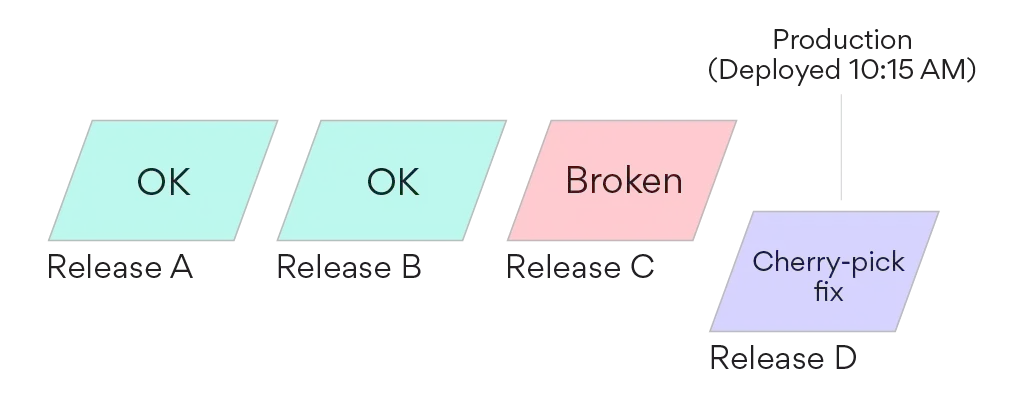
Normally there is a subtle danger in doing something like this. Let’s say a fix is made on both a cherry-pick and to the mainline:
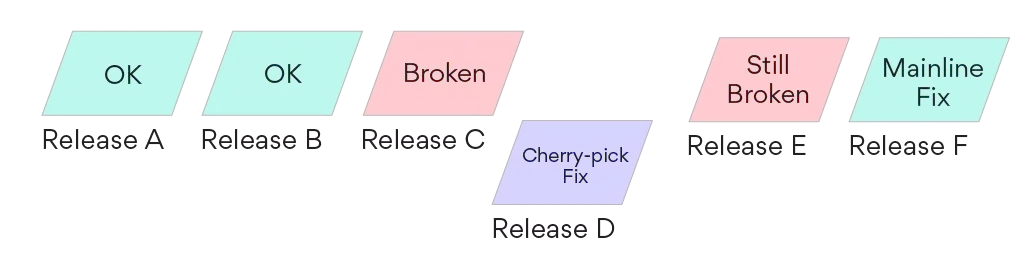
Resuming automatic deployments after a cherry-pick fix runs the risk of pushing the problem to production again. If the automatic deployment had run before Release F had been built, it could have pushed a new release (Release E) which was still upstream from the fix in the mainline.
However, this wasn’t a problem for George: the broken release range containing Release C automatically included all future releases. To allow normal deploys to continue, he marked the blocking broken release range as being fixed by both the cherry-pick commit and mainline commit. When the fix was available in the mainline (in Release F), the release activation system resumed automatic deployments.
Broken release ranges and their associated technology allow us to continue to ship application code quickly, safely, and at scale. In this blog post I will discuss a number of the features that we have build using broken release ranges, including:
Being able to set broken release ranges as blocking so that we can make sure that we do not push or roll back onto broken code.
Creating stability errors a special class of error which does not get broken release ranges.
Creating heuristics to detect error spikes so that we can find out about errors which increase in frequency.
Allowing engineers to create non-crashing broken release ranges so that we can track visual bugs etc.
Creating special logic around beta errors so we can avoid pushing new bugs to production.
Building integrations with our feature flag system so that we can understand how our errors are related to our uses of feature flags, and treat them accordingly.
Allowing engineers to configure “subscription information” so that new errors and warnings can be easily sent to the relevant teams.
Let’s first do a quick overview of the problem space, and why these systems are helpful to us.
Error reporting and shipping releases at Asana
As our engineering team has grown, the complexity of situations has grown too, and it has become increasingly important to handle issues quickly and easily. Furthermore, different issues affect different (and sometimes overlapping!) ranges of releases, and our release-range-based systems allow us to keep state around which releases are unsafe to deploy, and for what reasons.
There are a few aspects of Asana’s architecture that make our Application Stability process somewhat unusual:
Our large client bundle: Asana is a complex and interconnected single-page javascript app—about 3.5MB compressed at the time of this writing.
Running tens of releases in production: When a user loads a tab in Asana, that tab will download a version of the client bundle, and will continue running that version until the tab is closed—which can be days later.
Pinning client and mutation server releases: We have releases of our mutation server code that match 1:1 with bundles that the clients download. This allows product engineers to not have to worry about API versioning.
Pushing releases to production three times per day: This allows small fixes, changes, and updates to get to our users faster.
Building our own tools for error reporting and deployment—and tightly integrating them—allows us to efficiently handle complex scenarios around releases, flags, and multiple overlapping problems in code.
The three systems whose interaction we will describe are:
The Asana web application, running a web release on client browser and mutation server code. ¹
Airpedal ², our error reporting tool.
The Release Activation System, which is responsible for deploying the web application, both automatically and manually.
In the next few sections, I will explain some concepts used by these systems. Afterward, I will explain how Airpedal handles different kinds of crashes.
Airpedal Groups
An Airpedal Group is like a Sentry Issue or Rollbar Item. It represents a collection of occurrences of crashes that the system believes should be grouped together. In some systems there are complex heuristics for this, however at Asana we control both sides of the framework—error generation and error collection—so we can set up a situation where, in general, the system parses our errors into coherent groups that represent separate issues.
Each Airpedal group has an associated task in Asana.³ This task represents the work item of fixing the linked crash, and our workflow with them uses many of the work management features of our product, such as assignees, due dates, dependencies, multihoming, and comments. Some features of this tracking task can be configured from calling code, so that, for example, tasks for crashes in the domain migrator go directly to the Customer Scaling team’s Bugs Inbox.
Beta and production
When we deploy our code, we deploy it to one of two clusters: beta and production. The beta cluster gets code first, and is used only by Asana employees. We are very lucky that we make a product that is used by everyone in the company every day. Because our colleagues are using the beta cluster, we have robust quality assurance for our code before it goes live to production.⁴
It takes three to four minutes to complete the process of deploying a release, and about one minute to roll back to a release that was previously served. This is made possible by building server and client artifacts concurrently with running tests, making those artifacts available in S3, and then instructing our machines each to download the new server bundles and our systems to point page loads to the new client bundle.
Our normal automated push schedule is to deploy to our beta cluster every half hour, and to deploy to production three times a day. As part of the automatic production deploy, the Release Activation System will choose the newest web release which:
Has served enough beta traffic in terms of wall time minutes
Has served enough beta traffic in terms of page loads
Is not contained within any blocking Broken Release Ranges in Airpedal
Broken release ranges
A broken release range is a data model concept in Airpedal, which represents the range of releases that are affected by a particular issue.⁵ A broken release range is specified by a first broken release, which is the first release containing the code that causes the issue, and by one or more fixing commits. A release is considered to be within the range if it is a descendant of the first broken release, and not a descendant of any of the fixing commits.
An Airpedal group can have zero or more broken release ranges, representing discrete instances of that problem occurring. When a broken release range is created, the group’s task in Asana is created. When all broken release ranges for a particular group have been fixed, and their fixes have been deployed to beta, Airpedal automatically closes the task out, letting us know we’re done shepherding the fix.
A broken release range is either blocking or non-blocking. A blocking broken release range represents a problem bad enough that we want to make sure that it is not served to production users. This means that the Release Activation System will:
Decline to deploy releases within blocking broken release ranges to production.
Notify on-call engineers if the release currently being served in production is within a blocking broken release range.
Blocking broken release ranges allow us to keep state around which releases we consider safe to serve. In complex situations, where multiple issues and their resolutions may overlap, the system of blocking broken release ranges allows us to be confident that we will not roll back to bad releases in case of new problems, and that when we push new releases they will not contain issues that we already know about.
Error rates
A lot of the logic around broken release ranges is dependent on the concept of the error rate. This a rough measurement of how much is this crash occurring on this release, and is calculated by dividing the number of users affected (so that one pentester, or one very unlucky user crashing many times, doesn’t affect the calculation too much) by the number of page loads we have observed on the release. While the number of page loads might not formally be the measurement we’d prefer—perhaps a better denominator would be something like “user session minutes”—it seems to be a fairly reasonable proxy, and is easy to calculate.
Comparing errors using per-page-load rates—versus a measurement such as users affected per day—allows us to meaningfully compare errors that have just started with ones that have happened over many days, and allows us to automatically account for the effects of fluctuations in user traffic.
Now that we understand the concepts used by our error reporting systems, I’ll explain how the systems handle different kinds of crashes.
Handling new crashes
Airpedal creates broken release ranges where it observes crashes, setting the first broken release to be the earliest release where it observed a particular crash at a level that warranted concern. When Airpedal creates a broken release range for a particular group, it comments on the Asana task associated with that group. It also adds the current web on-call engineer as a follower of the task.
If we think we’ve fixed a crash, but then it continues or restarts in a release that is a descendant of a putative fix, Airpedal lets us know: It creates a new broken release range, and marks the associated Asana task as incomplete.
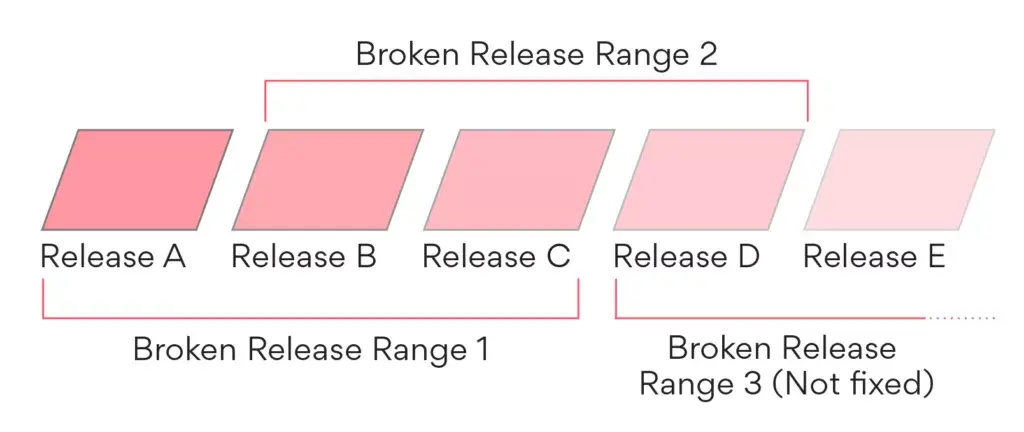
Because we run so many releases simultaneously, it’s important for this logic to be in the git dimension rather than the time dimension. Consider the following set of releases with a broken release range:

Even though Release C is the current production release, and new web clients will page load onto Release C, older clients can still be running Releases A or B. If Airpedal sees new errors on A or B, it will not react, even though they are new, because it expects errors to occur within the broken release range. However, new errors on Release C are not expected, since we have told Airpedal that the broken release range is fixed in Release C. If Airpedal sees new errors in or after Release C, it will make a new broken release range.
In production
Although we supply a dashboard UI, we want Airpedal to proactively tell engineers when something requires attention.
We notify our web on-call engineers for every new exception broken release range by adding them as followers to the associated Asana task, so we can’t afford to create broken release ranges for every Airpedal group. Due to a combination of factors⁶, we end up getting a lot of different exception groups, and many of them occur at extremely low frequencies, affecting sometimes only a handful of users in a week.
For new crashes in production, Airpedal will make a new broken release range only when the error count is higher than an absolute minimum and the error rate is higher than a minimum rate. The minimum number and rate are specified as constants in code. This filters out errors that are likely not worth addressing.
We also want to pay attention to this crash at the right level of urgency. We have a P0 threshold set to 1 in 3000 page loads. If a new error in production is occurring with a rate higher than this, Airpedal will mark the broken release range as blocking, although engineers also have the ability to override Airpedal’s automatic classification in either direction.
Since the Release Activation System notifies oncall engineers urgently when the current release on production is contained within a blocking broken release range, Airpedal creating blocking broken release ranges in production will create an urgent alert for oncall, so that they find out more quickly than simply the next time they check their Asana inbox.
In beta
If an error’s first occurrences are on beta, it is probably caused by code that has not reached production yet. We are ultra-conservative with these errors, and require web on-call attention to each one of them. Airpedal marks all new broken release ranges in beta as blocking, so they cannot be pushed to production.
This means that, in order to push new code after a beta broken release range is created, the web on-call engineer needs to
Determine the commit that causes the new issue, and ask Airpedal to mark the first release containing that commit as the first broken release of the broken release range
Commit a fix for the broken release range when they can
When the time for the next automated production deployment comes around, the Release Activation System will choose a release that is either an ancestor of the first broken release, or a descendant of the fix, depending on whether the descendant has been served for long enough, not contained in other broken release ranges, etc.
Handling crashes that spike in frequency
Above, I explained how Airpedal handles crashes we haven’t seen before. Airpedal also creates a broken release range if an existing error starts happening with a greater frequency on a particular release. For example, let’s imagine that there is an error that is currently happening to 10 users a day. It has a broken release range already, there’s a task tracking it, and a team intends to address the issue sometime in the next month. If that error suddenly starts happening to 200 users a day, we want to treat fixing it with a different level of urgency. For each release where an error is continuing to happen, Airpedal will compare the error rate on that release with the error rate across a set of background releases over the previous two weeks.
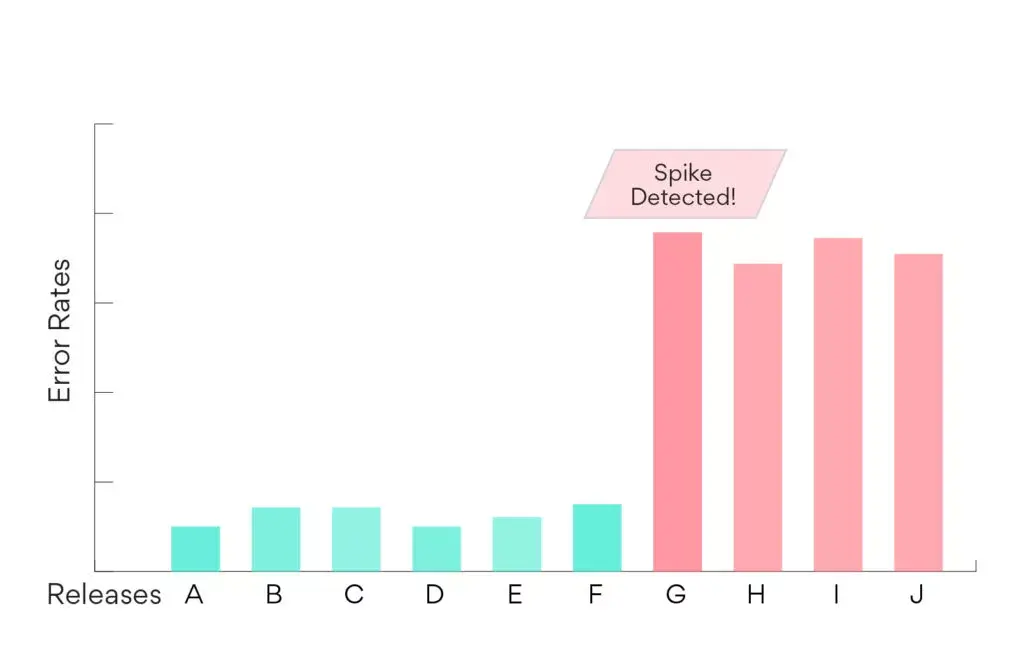
Diagram of detecting a spike against a background rate
If the error rate on a given release is above a certain constant times the background rate, we consider it to be a spike, and make a new (potentially nested) broken release range. A group’s background rate is the rate of occurrence for that group across the background releases. There are two subtleties we need to consider, however:
To get the correct calculation, we need to exclude prior fixed broken release ranges. The error may have occurred in the past at some enormous rate due to another cause, which we fixed. This needs to not influence the question of whether currently we are seeing a spike over the ambient background level
Sometimes rate calculations can be inaccurate when the number of page loads is low. For example, we might see two crashes within the first 2000 page loads. Would we keep seeing that rate with more page loads, or did we just get unlucky? To answer this question, we use a Beta distribution to model the error rate. Using the model, we can determine the chance that the spike we’re seeing will continue with more page loads. If there is at least a 95% chance that we’ll continue to see an elevated error rate with more page loads, we create a broken release range.
Handling crashes caused by flags
Asana gates our large new feature development behind flags, and we roll features out to users by turning flags on for incrementally larger percentages of the user base. Before features are launched to the public, we dogfood them in the beta cluster by turning the flags on for ourselves manually.
From an application stability perspective, crashes behind unlaunched flags don’t worry us like normal crashes in beta, since external users don’t have the flag enabled, and won’t see the crash. In Airpedal, we can mark a beta broken release range as beta only/behind unlaunched flags. This will make the broken release range non-blocking, and Airpedal will then disregard any future occurrences of the error on beta. However, if that crash ever happens on production—presumably because we launched the flag without fixing it—Airpedal will tell us immediately.
In production, Airpedal also queries our cluster configuration to know which flags are being tested. For each error, it checks whether the error happens mostly when a certain flag is on. If over 90% of a crash’s occurrences are associated with a particular flag, Airpedal will surface this.
Handling stability errors
As described above, broken release ranges model errors that occur due to code committed by engineers. If a crash happens for another reason—usually an outage of some kind in an upstream service, but sometimes things like malicious user activity—we can’t track it with a broken release range, since it doesn’t correspond to a particular release.
For example, if a Redis node fails over during a request and the request times out, then we do want to crash the backend server process waiting for that request, we do want to record that crash, but we don’t want to treat that crash as though it is possible to “fix” it by changing something in the code.
Stability errors allow us to model this concept. Airpedal groups which are marked as stability will not create broken release ranges. Crashes can be defined as stability errors directly in calling code (so our gRPC microservice clients, for example, can emit stability errors when their upstream service returns errors that aren’t due to malformed requests), or they can be specifically allowlisted in the Airpedal web application once we realize that a particular error can only be hit during a stability incident.
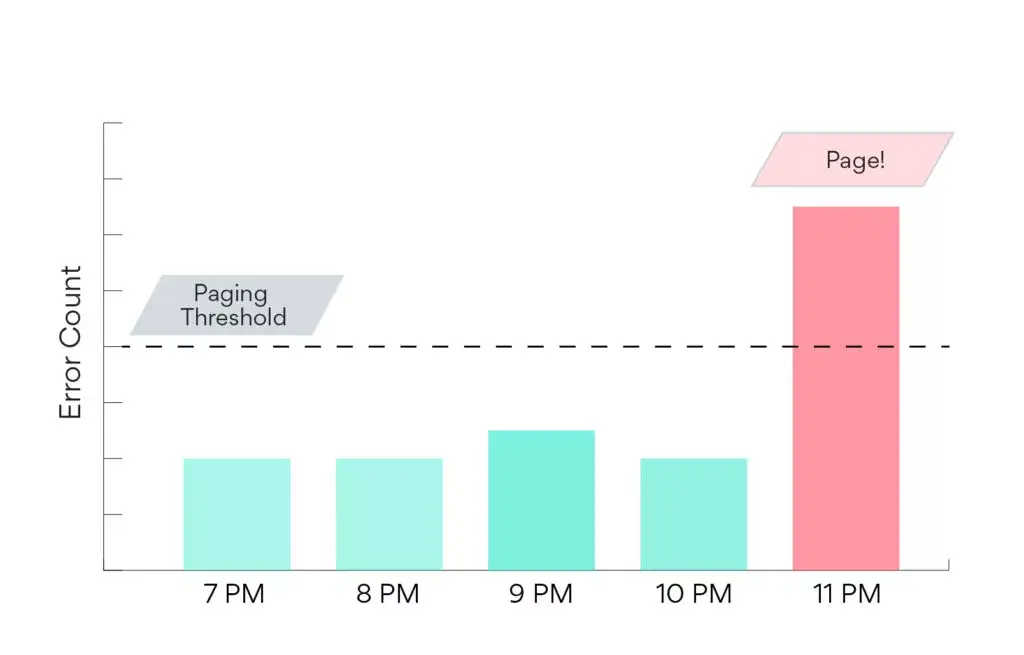
Because stability errors do not create broken release ranges, Airpedal has a secondary alerting mechanism for stability errors, called action rules. Action rules are similar to alerting rules in commercial error tracking systems, and allow the system to page on-call engineers⁷ when errors cross configured bucketed thresholds. An example of this would be a rule that states “page if this hits more than 60 users per minute every minute for four minutes in a row”. This allows the system to ignore short transient spikes (if it hits 2000 users in the first two minutes, and nobody in the third and fourth minute, we won’t page), that can be configured as per the upstream the crash is responding to.
Notably, action rules are defined in terms of errors per unit time, rather than errors per page load, per release as with broken release ranges. In other words, we think about Stability issues in terms of time, rather than git history. This makes sense because when we do have a stability issue, the errors occur on all of our currently-served releases roughly proportionally to their current traffic.
Handling visual bugs and other non-crashing issues
Not all bad problems are crashes! As anyone involved with building web products knows, there are many ways to break an application without causing crashes.⁸ Because blocking broken release ranges are the source of truth for whether given releases are safe to serve, Airpedal allows us to manually create blocking broken release ranges as well.
Manually-created groups have very little metadata: for example, Airpedal has no idea how many users saw a piece of bad CSS. All we can store is the related Asana task, a broken release range with a first broken release, and, hopefully, a fixing commit. However, this still prevents us rolling back to releases that have bad non-crashing bugs.
Urgent fixes and cherry-picks
A somewhat common scenario for web on-call engineers is to need to roll back a particular production release due to a problem, but also want to make sure the rest of the code in that release goes out promptly. This is what happened to George, in the story that begins this blog post.
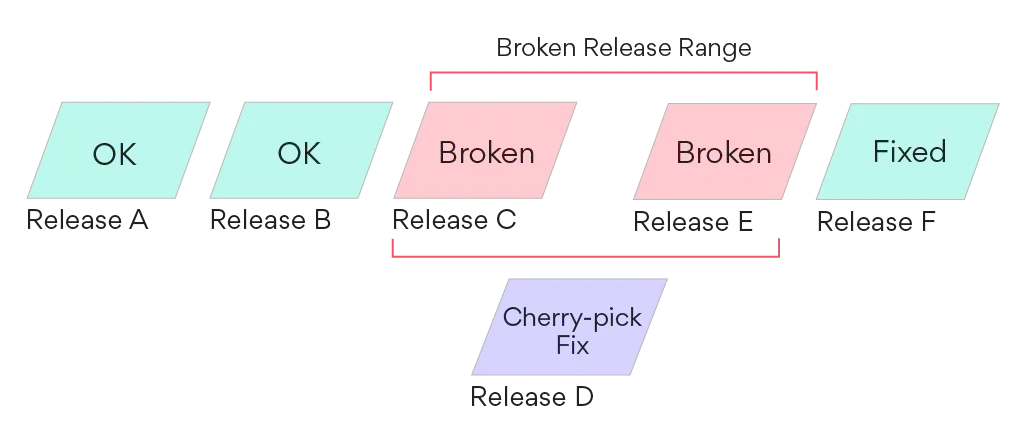
The ability to have multiple fixing commits on a broken release range allows us to model this kind of situation in which the git history of releases is not linear.
The workflow in this case would be something like this:
Push a bad release to production (oops!)
Realize we’ve pushed a bad release to production because Airpedal tells us that the release is contained in a blocking broken release range
Roll back production to a safe release
Create and merge a fix for the issue ⁹
Create a cherry-pick release where we cherry-pick the fix onto the original broken release
Mark the broken release range as being fixed by both the cherry-pick and the mainline revert
Manually test the cherry-pick release
Push the cherry-pick release to production
Because the broken release range has been fixed with the cherry-pick commit, the system understands that the cherry-pick release is safe to serve. It will also understand that any release in the mainline that has the fix will be safe to serve, as well, but it will decline to automatically deploy any of the broken releases to production.
Adding subscription information
The strong integration with Asana allows us to configure alerting and responsibility for different errors or areas of code. In the main Asana product codebase it is possible to annotate certain code paths, crashes, or warnings with subscription information. Subscription information refers to tasks or projects within our own instance of Asana. This means that by adding these annotations to the main product code, we can configure what happens to the tasks created for those crashes and warnings.
For example, if we know that a particular team is responsible for a specific remote job, we can specify this in code, and Airpedal will automatically put all errors that occur within that remote job in that team’s backlog. In fact, we encourage all engineers adding warnings to add subscription information for them. This allows them to be notified if/when their warning actually fires, versus having to poll the system to see if it happened or not.
Conclusion
We’ve built an integrated error-tracking and deployment system at Asana which allows us to ship releases to production with confidence. The system’s fundamental data model is the broken release range, which represents the relationship between code-related issues and releases. Broken release ranges allow us to model new crashes, crashes that spike in frequency, as well as non-crashing bugs. If an issue is severe enough that it should not be served to users, a broken release range can be marked as “blocking”, which affects which releases are deployed or rolled back. The system also integrates tightly with our own instance of Asana so our engineers can effectively track the work of keeping our application bug-free for our users.
¹ It’s worth noting that although the bulk of our product code is deployed as part of the web application push, we maintain a number of smaller, separate service-such as our reactive query server LunaDb, our pageload server, our revenue infrastructure service, etc., that are deployed separately, and are not currently served by these systems. Also, technically our remote jobs system also is part of the web release, however there’s additional complexity around these releases which is beyond the scope of this post. ² An homage to Airbrake. I wrote an article about a much earlier version of this system back in 2016. ³ That is to say, in Asana’s internal instance of Asana, where our engineers will be working; unsurprisingly, at Asana we use our own product quite heavily. ⁴ There are a few areas of code that don’t get as much QA internally—in particular, our admin and billing views, and the new user experience. We do our best to cover these in beta with black-box synthetic tests. ⁵ We only track problems caused by bad application code in broken release ranges; we refer to problems not caused by bad code, like outages in upstream services (e.g., database saturation) and malicious user activity, as Stability Errors. ⁶ E.g. quirks in our frameworks, users with weird browser extensions, the tendency of some browsers to translate exception messages, though the latter issue has mostly gone away lessened now that we have stopped supporting Internet Explorer. ⁷ This defaults to paging our infrastructure on-call engineer for stability errors, since the issue is most likely to be with the systems they are responsible for. ⁸ One recent real-life example at Asana: we briefly broke being able to add spaces to task titles in Boards view. ⁹ 99% of the time this is just a revert of the PR that caused the problem. We encourage engineers not to try to “roll forward” with fixes (since other issues can crop up) but rather to revert first and then unrevert later with fixes.



